
What is pim4b?
pim4b is a Product Information Management platform built for the automotive aftermarket. At its core it serves as a centralised single source of truth — aggregating product descriptions, technical specifications, pricing, media assets, and channel distribution rules into one managed database. Every connected sales channel draws from the same record, eliminating the inconsistencies that emerge when the same product is described differently across systems.
The platform covers a broad operational surface: catalog management, pricing logic, media handling, and multi-channel distribution. This case study focuses on one specific capability: the Data Aggregator — an AI-powered research agent that enriches product records by querying external sources and presenting structured, traceable results for analyst review.
Why catalog enrichment in the automotive aftermarket?
The automotive aftermarket operates at a scale that makes data management genuinely difficult. A single replacement part may be compatible with dozens of vehicle models, manufactured under multiple OE numbers, and produced by competing brands — each with their own symbols, specifications, and version histories. Managing that information is not only a data problem. It is a complexity one.
PIM solves the organisation challenge for data you already have. But the market does not stand still. New producers enter. New part versions are released. Established parts gain new vehicle applications as manufacturers release further variants. Staying current requires active, ongoing research — and that research falls on analysts.
Manual lookup follows a predictable, repetitive pattern: identify the OE number, open each relevant source in a separate browser tab, extract competition numbers, technical specifications, and vehicle applications, reconcile conflicts across sources, then transfer results into the catalog. For a catalog with hundreds or thousands of active part numbers, this becomes a significant operational burden — one that starts falling behind the moment it is finished.
The data that makes a product record complete
An enriched product record is only as useful as the quality of the data behind it. In automotive aftermarket, three categories of structured information determine whether a record is commercially complete — and each requires checking multiple external sources.
- Competition Numbers — Cross-references to equivalent part numbers from other aftermarket producers. Essential for commercial compatibility across supplier catalogues — without them, the product is invisible to buyers referencing a different manufacturer's numbering.
- Technical Parameters — Dimensions, materials, engine codes, emission standards, EAN codes, and other specifications that determine whether a part is the correct one for the application. These need to be accurate, consistent, and machine-readable.
- Vehicle Applications (K-Type) — The list of specific car makes, models, engine families, and production years a part is compatible with. This is the data that connects a product to a customer's actual vehicle — and it evolves as manufacturers release new variants.
Each of the three categories above requires querying multiple external databases, catalogues, and marketplaces. Sources disagree, use different symbols, and carry different information. Reconciling those differences manually is where the real analyst time disappears.
Workflow walkthrough
A — Query
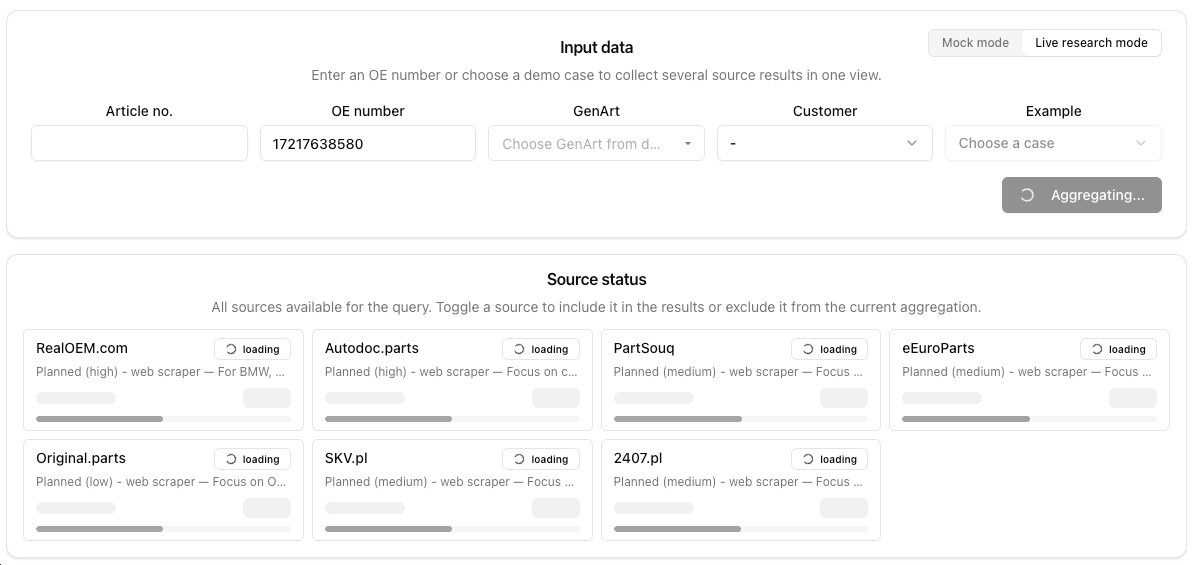
The analyst enters an OE number. The agent begins querying external sources simultaneously using two complementary strategies — structured extraction where sources permit it, and native AI web research where conventional automation is blocked. The Source Status Strip updates live as each source responds, showing which returned results, which returned partial data, and which returned nothing.
B — Candidate Grid

Results normalise into a unified parameter grid — sources as columns, data attributes as rows. Every candidate carries a confidence score (0–100%) reflecting data completeness and the quality of supporting evidence. A part compatible across several vehicle families may produce dozens of source columns, deduplicated and ranked. Cells with conflicting values are highlighted, giving the analyst an immediate visual overview of where disagreement exists.
C — Cross-Validation
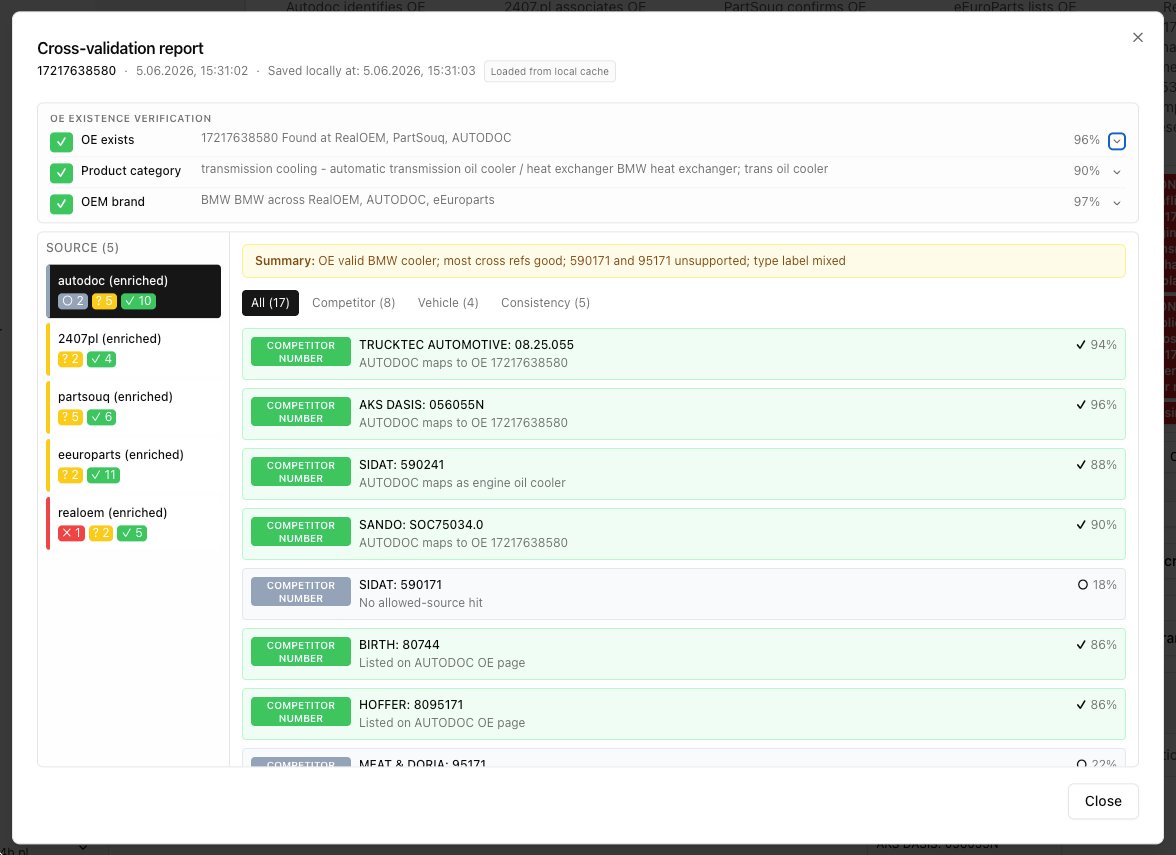
The analyst triggers a dedicated verification pass. The system runs a second AI query to check whether OE numbers are recognised, whether competitor cross-references are valid, whether vehicle applications are plausible for this part category, and whether sources agree or conflict on key values. A colour-coded report — confirmed in green, uncertain in yellow, conflict in red — surfaces issues explicitly before the analyst proceeds.
D — Draft Assembly
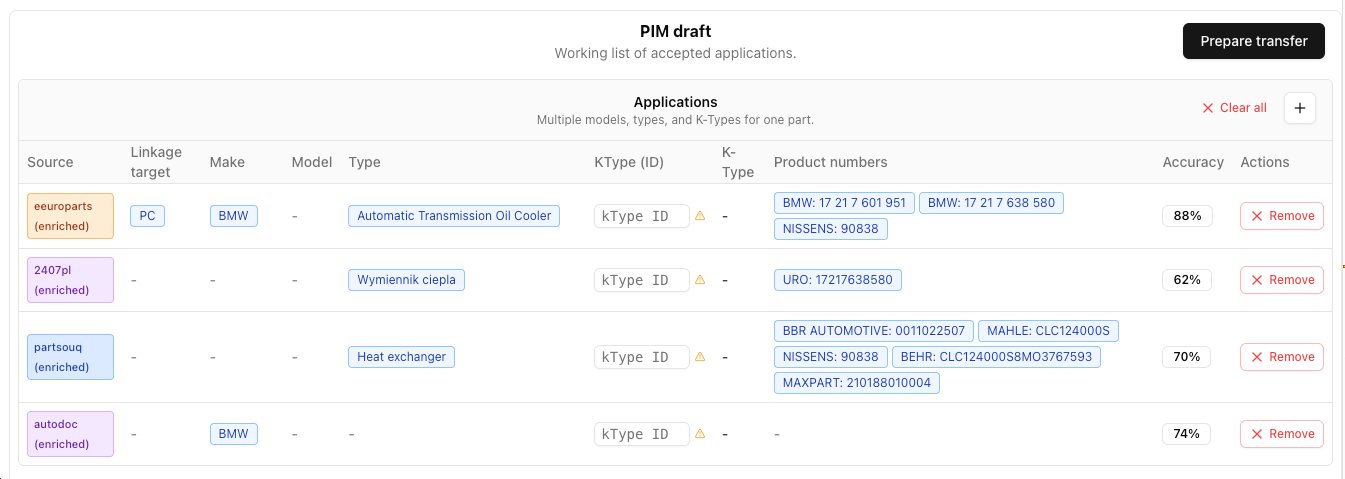
The analyst accepts fields directly from the candidate grid, building the PIM Draft progressively. Where sources agree and confidence is high, acceptance is straightforward. Where sources conflict, the analyst reviews the evidence behind each value and selects the one better supported. Fields absent from all sources can be added manually with a custom source note. Every accepted value retains its source name, confidence score, and the evidence text behind it.
E — Review and Transfer
The completed draft covers three sections: Vehicle Applications, OE Numbers, and Product Parameters — each entry with full provenance. The analyst adds a transfer note and confirms. The enriched record is written to pim4b and immediately available across all connected channels — no copy-paste, no reformatting, no loss of traceability.
What this really changes
Manual catalog enrichment does not disappear — it becomes smarter. The repetitive, tab-switching, copy-paste work that consumed analyst time is handled by the agent. What remains for the analyst is judgment: reviewing confidence scores, resolving cross-validation conflicts, and deciding which field-level values to accept.
The cross-validation layer is the part that matters most. Gathering data from multiple sources is not sufficient — aggregated data can still be wrong, inconsistent, or out of date. The system makes those conflicts explicit so the analyst can act on them, rather than discovering a data quality problem after it has propagated into the catalog.
The agent doesn't replace the analyst. It replaces the browser tabs.