

Introduction to AWS Glue ETL
AWS Glue is a serverless data integration service. It helps you prepare, move, and integrate data from various sources for analytics, machine learning, and application development. It essentially automates the Extract, Transform, and Load (ETL) process, making data preparation easier, faster, and cheap.
Benefits of using AWS Glue ETL for data processing
- Reduced Costs
- You only pay for the resources you use, eliminating the need for upfront infrastructure investments.
- Increased Productivity
- Glue automates many tasks, allowing you to focus on more strategic work.
- Improved Data Quality
- Glue can help you ensure that your data is clean, consistent, and ready for analysis.
- Greater Flexibility
- Glue supports a wide variety of data sources and destinations, giving you more flexibility in how you manage your data.
AWS Glue services in depth
Before we dive into some specific examples let us describe the services we chose in a little more detail.
AWS Glue ETL Job
An AWS Glue ETL job is a task within AWS Glue that handles Extract, Transform, Load (ETL) processes. It extracts data from various sources, like databases and data files, transforms it, and loads it into target data destinations such as databases. AWS Glue ETL jobs can be scheduled to run at specific intervals or triggered in response to events, such as the arrival of new data. They are fully managed, meaning AWS handles the infrastructure provisioning, scaling, and monitoring of the ETL jobs, allowing users to focus on defining and implementing their data transformation logic without worrying about the underlying infrastructure.

AWS Glue Data Catalog
AWS Glue Data Catalog is a centralized metadata repository within the AWS Glue service. It acts as a comprehensive registry for information about your data assets, offering a unified view of their location, lineage, ownership, and quality. This centralized approach empowers several key functionalities: data discovery becomes effortless, data governance is facilitated through efficient organization, and data management processes are streamlined thanks to a consolidated overview. In essence, the Glue Data Catalog serves as the central nervous system for your data landscape within the AWS Glue ecosystem.

AWS Glue workflow
AWS Glue workflows orchestrate the execution of multiple ETL (Extract, Transform, Load) jobs within your data lake, establishing a cohesive data processing pipeline. These visual workflows define the sequence and dependencies between jobs, ensuring data flows seamlessly through various stages. AWS Glue workflows offer a user-friendly interface for building and managing complex data processing logic, eliminating the need for manual scripting. They integrate seamlessly with other AWS services like crawlers, classifiers, and Spark, enabling a comprehensive data preparation and transformation environment. By leveraging AWS Glue workflows, you can streamline your data pipelines, improve data quality, and gain deeper insights from your data.
Simplified example of workflow
AWS Glue Crawlers & Classifiers
In the context of AWS Glue, crawlers and classifiers work in tandem to streamline data discovery and organization within your data lake. Crawlers act as automated scouts, traversing various data stores like Amazon S3 buckets or databases. They analyze the discovered data, inferring its structure (schema) and metadata. Classifiers provide an additional layer of intelligence by applying predefined or custom rules to the data. This enables classifiers to identify file formats (e.g. CSV and JSON), extract specific data types, and categorize content for better management and analysis. Classifiers can be built-in (like those supporting common formats) or you can tailor your own to suit specific data patterns. Together, AWS Glue crawlers and classifiers automate the otherwise cumbersome process of cataloging and preparing data for further ETL (Extract, Transform, Load) processes, making data-driven insights more accessible within your AWS ecosystem.

AWS IAM
AWS Identity and Access Management (IAM) empowers you with granular control over user and application access to your AWS resources. This comprehensive service allows you to centrally manage permissions, ensuring only authorized entities can perform specific actions. With flexible credential options like passwords, access keys, and temporary tokens, IAM fosters a secure and well-defined access environment within your AWS infrastructure.

AWS S3
AWS S3 (Simple Storage Service) is a highly scalable, durable, and secure cloud-based object storage service. With S3, you can store virtually unlimited amounts of data in any format, such as documents, images, videos, logs, or code. S3 offers a range of storage classes optimized for different use cases, from frequently accessed data to long-term archival, balancing cost and performance. It also integrates seamlessly with other AWS services, making S3 a cornerstone for diverse cloud architectures and a compelling choice for storing and managing your data in the cloud.

Amazon Athena
Amazon Athena, a serverless interactive query service by AWS, enables seamless analysis of data stored in Amazon S3 using standard SQL. Its features include support for ANSI SQL, integration with diverse data formats in S3, automatic scalability for large datasets. With its integration capabilities with AWS Glue, Athena streamlines data analysis workflows, making it suitable for various use cases such as log analysis, ad-hoc querying, and business intelligence reporting.

Understanding the weekly upload process
To better understand the functionalities offered by AWS Glue ETL let’s take a real-life example that will serve as an excellent teaching base for all fascinating features it provides.
For this study’s example let’s delve into the scenario of a weekly data upload process of a simplified data structure containing information about vehicles. Let’s assume that we receive CSV files with the same schema, and we want to only retrieve unique rows.
Our final flow would look like this:
- User uploads CSV files containing large number of objects to s3 throughout a week
- Once a week Aws Glue Data Crawler is triggered by a schedule
- ETL Job gets triggered on Crawler success
- ETL Job selects unique rows and appends them to appropriate glue table

In order to achieve this, we are going to take some of the core AWS Glue functionalities and connect them together into a powerful upload machine. To be specific we are going to take a closer look at those particular features:
- ETL Jobs
- Crawlers
- Classifiers
- Triggers
- Databases
- Tables
Setting up AWS Glue ETL for data processing
Configuring data sources and destinations
- Configure data sources by creating AWS S3 Source Bucket
- Configure destination AWS S3 Bucket where transformed data will be stored.
- Configure AWS Glue Database
Creating data crawlers and classifiers
- Create data classifiers for csv file
- Create data crawler by providing few key properties
- Data source set to source S3 Bucket
- Previously created Classifier
- Previously created Glue Database
- Set output to sub-directory in destination S3 Bucket
- Create appropriate AWS IAM role for crawler
- Set execution policy to scheduled- weekly
Creating data transformation jobs using AWS Glue ETL
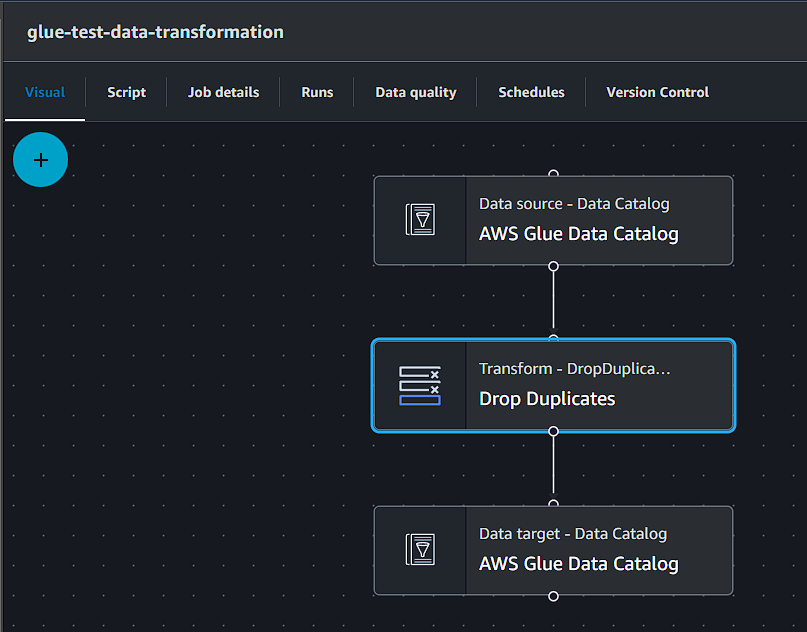
- Create ETL Glue job within AWS Glue
- Set source to AWS Data Catalog with path set to table for raw data in Glue Database
- Add Transformation “Drop Duplicates”
- Set destination to AWS Data Catalog with path set to table for processed data in Glue Database
Improving observability of the process
- Configure S3 space for AWS Athena
- Connect to AWS Glue database using Athena
- Inspect both tables
Automating the weekly upload process with AWS Glue ETL
- Set up Triggers to automate launching ETL Job on Crawler run success
Monitoring and troubleshooting data processing with AWS Glue ETL
- Monitor ETL job executions and performance metrics using AWS CloudWatch.
- Utilize logging and monitoring features of AWS Glue to troubleshoot any issues during data processing.
- Set up alarms and notifications for processing failures or performance bottlenecks.
Best practices for optimizing AWS Glue ETL for weekly uploads
- Fine-tune ETL job parameters for performance and cost efficiency.
- Utilize built-in caching mechanisms and partitioning strategies for optimization.
- Regularly review and optimize data processing operations for scalability and reliability.
Conclusion and next steps
The provided guide offers a structured approach to setting up AWS Glue ETL for data processing. While this serves as a fundamental example, it’s important to recognize that AWS Glue’s capabilities extend far beyond these foundational steps. As you move forward, feel free to explore more complex scenarios and utilize additional features offered by AWS Glue to tailor solutions to your specific business needs. Remember to embrace the best practices provided and seek innovations to unlock the full potential of your data infrastructure in the cloud.


